We are publishing the RAMCloud sources to GitHub. We are planning to merge them to PlatformLab/RAMCloud/master. We are still making some trials, please forgive us for some glitches.
Contents)
- Cluster Outline
- User's Guide
- User setup
- Running RAMCloud
- GitHub Repository for RAMCloud for the ATOM server.
- Development and enhancement
- Performance result:
- clusterperf.py
- TBD) recovery.py
- System administrator's guide
- Adding user with dedicated script
- Hardware maintenance
- GitHub Repository for NEC tools for the ATOM server
- Security solution
- For management server setup
- Setup guide
- Config files
- Stanford's ATOM Cluster - configuration, etc
- System photograph
- Server module specification
- Network connection
Cluster Outline)
Basically the procedure is the similar to rccluster except that:
NOTE) I have created a repository for test in /home/satoshi/ramcloud-dpdk.git and tested. You can clone the latest ramcloud on ATOM for testing. Please try it. The instruction is written below.
- The cluster has 132 ATOM servers ( Total : 1,056 cores, 4.1TB DRAM, 16.5 TB SSD) connected to dedicated management server 'mmatom.scs.stanford.edu', which is directly connected to the Internet. Please take a look at System configuration below for detail.
- Unstable server can be disconnected with management tool, and the continuous IP-address/hostname given. IP-address and hostname is always associated. You will find the details in System-Administrator's guide:Hardware maintenance.
User's Guide)
User setup)
- ssh login to management server 'mmatom.scs.stanford.edu' with public key authentification and the special SSH port.
- Install your 'key pair for the cluster-login' to ~/.ssh . For existing RAMCloud users, it is already copied from your home directory.
- Add the cluster-login-public key to ~/.ssh/authorized_keys .
Note)
- Your home is shared with all the ATOM servers with NFS, so you can login to all atom servers with public key authentification.
- Do not copy your private key for mmatom login. Please create different key pair to ssh to AROM cluster from mmatom.
- keypair can be generated with the command such as:$ ssh-keygen -t rsa -b 2048
- To avoid ssh Errors like 'Permission denied (publickey)':
Do not add passcode for the keypair for ATOM cluster login. You just type 'return' for passcode request of 'ssh-keygen'.
No group/other access permission for ~/.ssh and ~/.ssh/autorhized_keys.
0700 for ./ssh directory, 0600 for ./ssh/authorized_keysEach public_key in ~/.ssh/authorized_keys needs to be a single line without line break.
- Add the cluster-login-public key to ~/.ssh/authorized_keys .
- Initialize known_host:
- You can use /usr/local/scripts/knownhost_init.sh
- Usage) /usr/local/scripts/knownhost_init.sh <ServerNumberFrom> <ServerNumberTo>
If the host is already initialized result of 'hostname' on remote machine is displayed, otherwise you are prompted whether you will add the host to known_host database, where you should type 'yes'. - Example)
$ knownhost_init.sh 1 20
atom001
atom002
:
- Usage) /usr/local/scripts/knownhost_init.sh <ServerNumberFrom> <ServerNumberTo>
- Note) You may see the following error:
- 'Permission denied (publickey). '
- If you follow 2.a, 2.b., it maybe because because the remote user information is not created on atomXXX. We do not use NIS or LDAP so far. You need ask your administrator to setup remote user on atomXXX. See : 'System administrator's guide' below.
- You can use /usr/local/scripts/knownhost_init.sh
Compile RAMCloud on the host 'mmatom' )
- Git clone from RAMCloud GitHub fork, which is pre-tested for the ATOM cluster. Directory structure is similar to the original Stanford RAMCloud.
$ git clone https://github.com/SMatsushi/RAMCloud.git
$ cd RAMCloud
$ git checkout dpdk
$ git submodule update --init --recursive
- Note) This branch in the fork is a branch from :
PlatformLab/RAMCloud/master : commit e8a64639bc8a38e15b0c49aa2767fd45f2d60c6b
Date: Fri Aug 14 13:18:58 2015 -0700
No tag is added,
- Compile RAMCloud as typing make without any argument.
$ make
Note)
Following make options are now default and specified in GNUmakefile. (To be modified to match original RAMCloud)Debug=noARCH=atom
CC, CXX, AR is directly specified in order to use /usr/bin/gcc (4.8.3) and /usr/local/bin/gcc44 (4.4.7).
Tools below are located in ./scripts/ManagementTools so far. Please set your path or copy them into your scripts/bin directory.
- mmres/mmres.py, knowhost_init.sh, ipmiaw2, mmfilter
Run benchmark or application samples)
- Preparation:
- You need to have RAMCloud compiled.
- Reserve ( Lease ) ATOM servers with /usr/local/bin/mmres
- mmres has been ported from rcres. It manages resources for RAMCloud, eg. backup file, and DPDK resource file, etc. The backup replica is preserved until the mmres lease expires, so you can reuse the backup in different program while the lease continues.
- Check usage with: $ mmres --help
Example)$ mmres ls -l
$ mmres ls -l atom10-35 or $ mmres ls -l 10-35 // print range
$ mmres lease 14:00 atom10-35 -m 'Comment here!!'
- Note)
- Use local time on the server. Please check the local time with 'date' command before trying lease. 'mmres' does not consider user's timezone so far (python library's limitation....).
- Edit the following line in scripts/config.py for your servers reserved. Default is range(1,11) which means atom001 to atom010.
> for i in range(1, 11):
> hosts.append(('atom%03d' % i,- Now working for get node information from mmres database like PlatformLab/RAMCloud/master.
- Now you can spawn benchmark or application tasks from mmatom with python scripts.
- The scripts in scripts directory are customized for the ATOM Cluster so that we can run RAMCloud tests with default option
- The scripts in scripts directory are customized for the ATOM Cluster so that we can run RAMCloud tests with default option
Limitations) to be fixed....
- You will see WARINGs '(server not responding)'. They are seen in the normal job completion.
- A lot of DPDK debug messages starting with "EAL or PMD" is shown in stdout. Now fixing..
Quick Hack: Run through /usr/local/bin/mmfilter like:
$ mmfilter scripts/clusterperf.py basic
- Run clusterperf.py) It's default parameter is equivalent to the , which is replica=3, server=4, backup=1
$ scripts/clusterperf.py
Limitation)
- Fails after fifth test at "readDistRandom" out of 9 tests, after "multiWrite_oneMaster". Debugging now.
- Run clientSample) The simple client code.
- $ cd clientSample
- $ make
- $ make run
- or $mmfilter make run
- Note) Now it successfully completes after original 1M iterations.
- Run recovery.py)
- Now debugging. FastTransport bug fix should have been in, but still fails.
As we had some bugs in scripts/*.py, we put the fix in dpdk-recovHang branch in the fork SMatsushi/RAMCloud.
- Now debugging. FastTransport bug fix should have been in, but still fails.
Analysis or Debugging)
- Subcommands:
- scripts/clusterperf.py uses run function defined in scripts/cluster.py.
- cluster.py referes common.py for sandbox. Through common.py, default setting in config.py is referred.
- Useful options in the most python scripts.
- -v for verbose, - -dry (Note that two dashes for dry) for dry run (just printing command and create log directory)
- There are four standard transport setting for ATOM server, which can be specified with -T or --transport option. Please take a look at scripts/config.py for the option.
- Result and logfile:
- Print out in the server or client is forwarded to standard out (screen)
- Log messages, printed by RAMCLOUD_LOG(loglevel, format, args..) are stored in logs directory.
- There are four log levels (ERROR, WARNING, NOTICE, DEBUG), DEBUG log is only stored when the log level is debug. Higher level log message is printed even with lower log mode.
- Log level is specified with -l or --logLevel option of any python script.
- Log files are stored in directory with numbers meaning "%date%time" under ./logs directory where the command is executed. Normally the top level, where obj.* and scripts directory exist.
- Useful command is located in /usr/local/bin which are:
- logCleanup.sh : Cleanup log directories. Without any arguments, it looks for log directory under current directory and ask if delete it. You will see its help with -h option.
- logSummary.pl : Print summary of logs in the log directories. You can run it in the log directory or specify the directory as argument. Check its options with -h option. Cluster.py or other scripts must be executed with NOTICE or DEBUG option for the script to analyze coordinator log for server id.
- Useful command is located in /usr/local/bin which are:
Performance result)
Clusterperf.py
Note)
- Basic.read100 takes 15us on CentOS 7.1 and DPDK 2.0 with the latest release on GitHub. We are now debugging it.
Please take a look at /usr/include/rte_version.h for DPDK version. See also: http://dpdk.org/doc/api/rte__version_8h.html - We are now trying to move the disturbing DPDK log from standard out to some logfile. mmfilter is the filter to remove the message from stdout.
Measured on Wed 25 Feb 2015 12:31:42 PM PST :
basic.read100 13.456 us read single 100B object (30B key) median
basic.read100.min 12.423 us read single 100B object (30B key) minimum
basic.read100.9 13.837 us read single 100B object (30B key) 90%
basic.read100.99 17.698 us read single 100B object (30B key) 99%
basic.read100.999 24.356 us read single 100B object (30B key) 99.9%
basic.readBw100 4.7 MB/s bandwidth reading 100B object (30B key)
basic.read1K 20.425 us read single 1KB object (30B key) median
basic.read1K.min 19.593 us read single 1KB object (30B key) minimum
basic.read1K.9 20.786 us read single 1KB object (30B key) 90%
basic.read1K.99 24.306 us read single 1KB object (30B key) 99%
basic.read1K.999 36.569 us read single 1KB object (30B key) 99.9%
basic.readBw1K 33.4 MB/s bandwidth reading 1KB object (30B key)
basic.read10K 52.461 us read single 10KB object (30B key) median
basic.readBw10K 125.6 MB/s bandwidth reading 10KB object (30B key)
basic.read100K 358.567 us read single 100KB object (30B key) median
basic.readBw100K 187.6 MB/s bandwidth reading 100KB object (30B key)
basic.read1M 3.449 ms read single 1MB object (30B key) median
basic.readBw1M 212.1 MB/s bandwidth reading 1MB object (30B key)basic.write100 43.307 us write single 100B object (30B key) median
basic.write100.min 41.031 us write single 100B object (30B key) minimum
basic.write100.9 47.528 us write single 100B object (30B key) 90%
basic.write100.99 86.543 us write single 100B object (30B key) 99%
basic.write100.999 38.363 ms write single 100B object (30B key) 99.9%
basic.writeBw100 542.6 KB/s bandwidth writing 100B object (30B key)
basic.write1K 63.481 us write single 1KB object (30B key) median
basic.write1K.min 60.453 us write single 1KB object (30B key) minimum
basic.write1K.9 66.720 us write single 1KB object (30B key) 90%
basic.write1K.99 126.391 us write single 1KB object (30B key) 99%
basic.write1K.999 41.500 ms write single 1KB object (30B key) 99.9%
basic.writeBw1K 4.9 MB/s bandwidth writing 1KB object (30B key)
basic.write10K 199.648 us write single 10KB object (30B key) median
basic.writeBw10K 12.0 MB/s bandwidth writing 10KB object (30B key)
basic.write100K 1.508 ms write single 100KB object (30B key) median
basic.writeBw100K 17.8 MB/s bandwidth writing 100KB object (30B key)
basic.write1M 41.949 ms write single 1MB object (30B key) median
basic.writeBw1M 21.8 MB/s bandwidth writing 1MB object (30B key)# RAMCloud multiRead performance for 100 B objects with 30 byte keys
# located on a single master.
# Generated by 'clusterperf.py multiRead_oneMaster'
#
# Num Objs Num Masters Objs/Master Latency (us) Latency/Obj (us)
#----------------------------------------------------------------------------1 1 1 23.0 22.99
2 1 2 28.3 14.15
3 1 3 33.2 11.07
9 1 9 49.5 5.5050 1 50 168.7 3.37
60 1 60 235.5 3.93
70 1 70 209.1 2.99
Recovery.py
System administrator's guide)
Adding User)
So far we do not use NIS/LDAP for account management. Please use a script to setup new users.
NOTE)
User setup command onto ATOM cluster )
- NOTE)
- To run the following command, you must already be a privileged user among the management server and all the atom servers.
Please ask us to make or delete privileged users for the cluster. - <User*> below are account-name on mmatom. <User*> must be non-privileged user.
- To run the following command, you must already be a privileged user among the management server and all the atom servers.
- Add user(s) )
- $ /usr/local/bin/mmuser <User1> [ <User2> .... ]
- Delete user(s) )
- $ /usr/local/bin/mmuser -D <User1> [ <User2> ....]
Hardware maintenance)
- GitHub repository for NEC Tools for the ATOM Server
- The product name of the server is NEC Micro Server DX1000. Please refer repository for the product.
- Procedures:
- $ git clone https://github.com/SMatsushi/NECTools.git
- You will find scripts in NECTools/DX1000/scripts
- Getting module's slot/chassis information and Mac address for a hostname or IP address.
- You will find the information in mmatom: /etc/hosts :
IPaddress hostname Mac Address Installed slot and host port connected.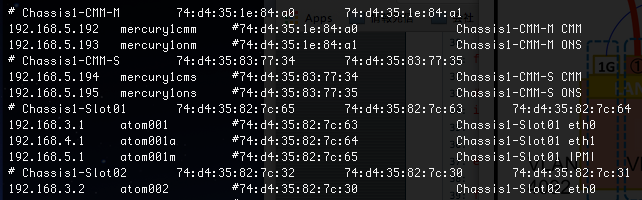
- For atomXXX(Y), XXX is always corresponds to final digit of IP address:
eg. atom100 == 192.168.3.100, atom110a == 192.168.4.110
- You will find the information in mmatom: /etc/hosts :
Security solution)
- SSH into management server
- Job spawning to cluster servers from management server
- Cluster management
- Server console
- IPMI to CMM, BMC
- USB connection to ONS from front panel
For management server setup)
- Setup guide
- Config files
Stanford's ATOM Cluster - configuration, etc)
1. system photograph)

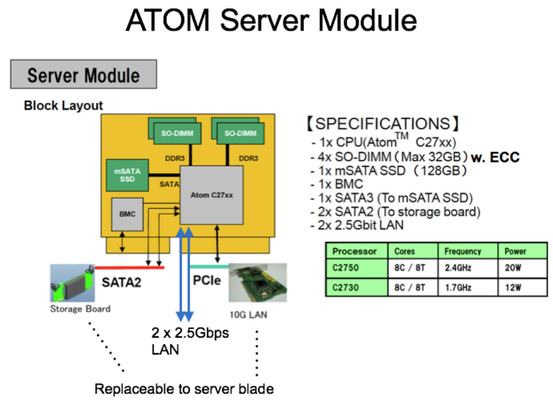
2. ATOM server module specification)

- 3 chassis are installed (The rack in above picture contains 16 chassis.)
- Installed ATOM modules are with C2730 (1.7GHz, 8 core/8 threads, 12 W)
3. Network connection)
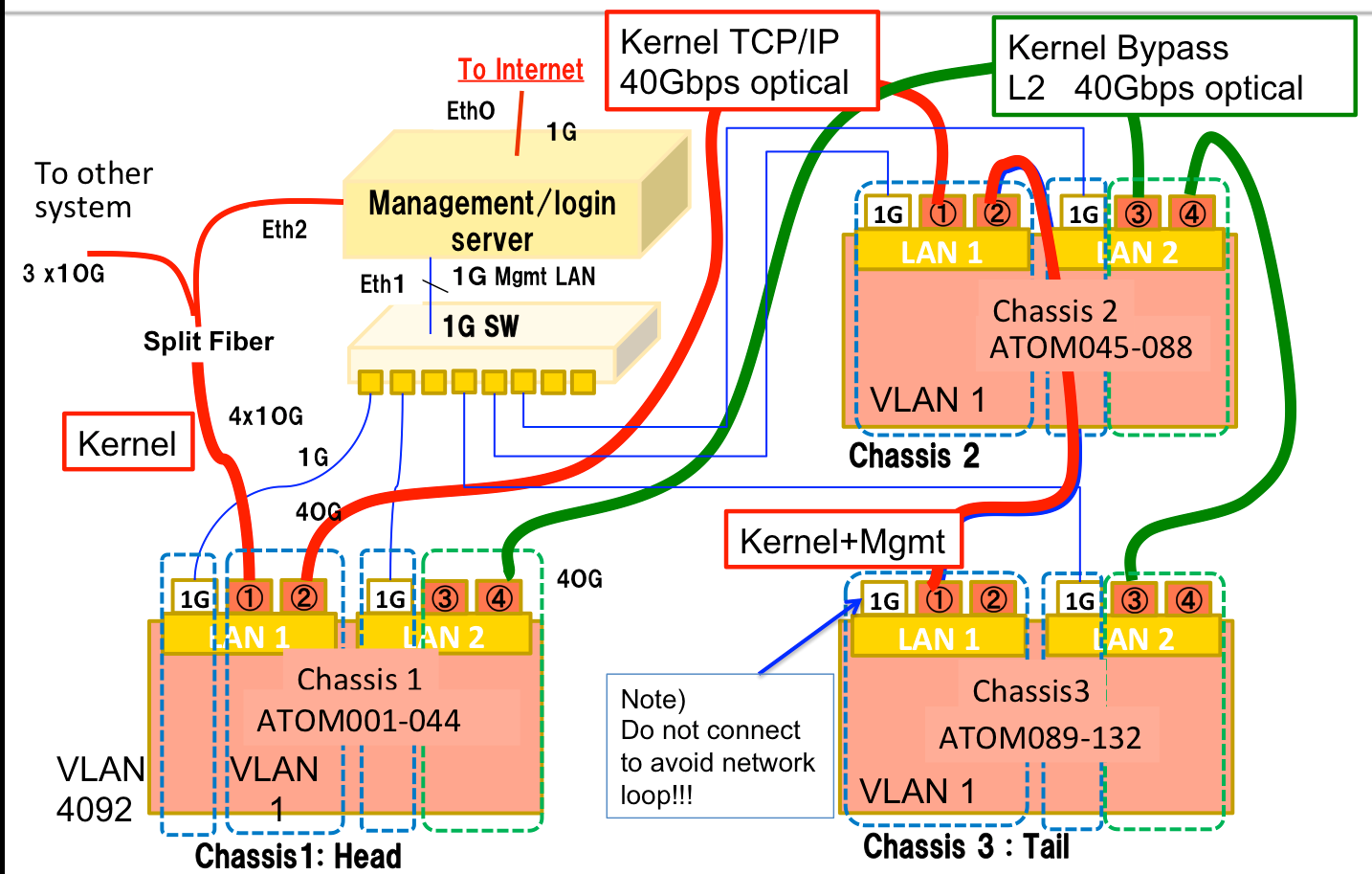
- Due to historical reason and considering future experiment, VLAN configuration is different in chassis
- Management server is directly connect to the internet, the cluster is isolated from other Stanford servers.
- Management server works as firewall, login server, firewall, NIS server, DHCP server, and PXE server for reconfiguring ATOM servers.