Preliminary results running FacebookHadoop workload under different environments:
After fixing timetracing in DpdkDriver in commit `c16fa4c`, it became clear that the ~15us latency at 99% was not due to network queueing delay. In addition, it looks more like kernel jitter because large gap in the time trace on the server side cannot be pinpointed to a fixed location.
It appears that the kernel compile-time option `CONFIG_NO_HZ_FULL`, which is essential for full-dynticks mode, is not set by default on Ubuntu 15.04 & 16.04. This can be checked by `grep NO_HZ /boot/config*`. Therefore, to turn off the timer interrupts, use Ubuntu 14.04 or compile your own kernel.
After slicing DpdkDriver::receivePackets and ObjectPool::construct with timetraces, it appears that the 16us jitters are spread (evenly?) across all the slices.
It seems like the ~15us (or 30000 cycles) jitters are not due to SMI (Service Management Interrupt) that are invisible to the kernel. This can be verified by running the `user_loop` test program with `THRESHOLD_CYCLES` defined to 100000 and reading msr 0x34 before and after the test program. Here is a sample output:
The number of jitters printed matches the delta of the two msr 0x34 readings.
(PS: Today I have to do a kernel upgrade in Ubuntu, it turns out to be really simple: http://askubuntu.com/a/236458)
Linux kernel 4.9 introduced a new hardware latency tracer(Documentation/trace/hwlat_detector.txt). By setting the `tracing_thresh` to 10us, I got the following output:
It doesn't look very useful as it only records the maximum jitter observed (this behavior can be verified at http://lxr.free-electrons.com/ident?v=4.9;i=get_sample).
It turns out that the 15us jitter is somehow related to CPU power management. I followed the configuration documented in a Dell technical white paper "Controlling Processor C-State Usage in Linux". Running `turbostat --debug sleep 10` again showed that there were still 8 SMI per second but the CPU were mostly staying in c1 state. The 15us jitters disappeared after this re-configuration, which could be verified via both `user_loop` and my "slice-ObjectPool-construct" experiment. This article[1] provides an explanation why the power-saving states could result in latency spikes. However, that is a different scenario and doesn't explain the earlier results of our `user_loop` test since the CPU is running in a tight loop. The jitter is probably due to some other thing correlated with C-states.
The longer SMI-induced jitters are harder to eliminate on the "HPE ProLiant m510 Server Cartridges in HPE Moonshot Systems". It requires disabling the "Memory Pre-Failure Notification" in the BIOS[2]. HP provides the `conrep`[3] utility to automate this task but it failed the platform check ("ProLiant m510 Server Cartridge" not in supported platform list) after I installed it from the apt repository. And I failed to find the "Service Options" when I tried to do it manually at boot-time following the instructions here[4].
PS: According to [5,6], "Intel Processor Trace can be used to trace SMM code", though I am not sure why `perf script` failed to show that in the trace output.
[1] "Are hardware power management features causing latency spikes in my application?" https://access.redhat.com/articles/65410
[2] "Configuring and tuning HPE ProLiant Servers for low-latency applications": https://www.hpe.com/h20195/v2/GetPDF.aspx/c05281307.pdf
[3] https://downloads.linux.hpe.com/SDR/project/stk/
[5] https://xem.github.io/minix86/manual/intel-x86-and-64-manual-vol3/o_fe12b1e2a880e0ce-1708.html
[6] https://www.slideshare.net/pipatmet/intel-processor-trace-what-are-recorded
The document "Low Latency Performance Tuning for Red Hat ENterprise LInux 7" is pretty comprehensive and has covered most of the tuning techniques I have read so far.
Mellanox DPDK is now based on DPDK 16.11 instead of 2.2. In its quick start guide[1], it also mentions that unnecessary SMIs used for Power Monitoring and for Memory PreFailure Notification should be disabled. A more comprehensive guide on performance tuning for Mellanox adaptor cards can be found here: https://community.mellanox.com/docs/DOC-2489.
[1] http://www.mellanox.com/related-docs/prod_software/MLNX_DPDK_Quick_Start_Guide_v16.11_2.3.pdf
All you need to know about Intel PT (and perf, in general):
http://halobates.de/blog/p/category/pt
https://github.com/01org/processor-trace/tree/master/doc
https://perf.wiki.kernel.org/index.php/Tutorial
http://vger.kernel.org/~acme/perf/
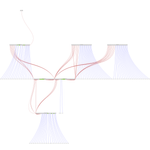
The cluster diagram at Cluster Intro is out of date. I created a new one using https://github.com/glaville/graphviz-infiniband-topology. It's kind of ugly but does the work for me.
An excellent explanation of how the NIC and its driver work collaboratively to send/receive packets: http://stackoverflow.com/questions/36625892/descriptor-concept-in-nic. The DPDK performance optimization guidelines (https://software.intel.com/en-us/articles/dpdk-performance-optimization-guidelines-white-paper) mention a bit more on DPDK-specific config options like `RX_PTHRESH`, `RX_WTHRESH`, etc.
The main problem of using TSC is that there is no obvious way to convert cycles to nanoseconds. The Intel docs state that Invariant TSC runs at a constant rate, which may differ from the processors' realtime frequency. The Linux kernel computes this TSC frequency by counting how may TSC cycles occurs between two hardware timers. The result can be displayed by `dmesg | grep TSC`. On the CloudLab m510 machines, the command above outputs something like "[ 0.000000] tsc: Fast TSC calibration using PIT ... [ 3.760036] tsc: Refined TSC clocksource calibration: 1995.379 MHz". RAMCloud currently uses `gettimeofday` to estimate the TSC frequency. To get a sense of how accurate it is, I redo the estimation using the newer `clock_gettime` with different clock sources. Here is the result:
It appears that clock MONOTONIC_RAW 1) gives the most consistent result across the cluster as well as multiple runs and 2) is the only one whose result matches the 1995.379 MHz computed by kernel. However, does it suggest clock MONOTONIC_RAW gives the most accurate estimate? I don't know yet.
Finally, some posts/articles that I find useful to read:
http://oliveryang.net/2015/09/pitfalls-of-TSC-usage/
http://stackoverflow.com/questions/6498972/faster-equivalent-of-gettimeofday
https://randomascii.wordpress.com/2011/07/29/rdtsc-in-the-age-of-sandybridge/
After calibrating the TSC clocks on different machines and merging the time traces, it's easy to compute the one-way propagation delay of each packet. If you order the delays of all the outbound DATA/ALL_DATA packets from one client by their TX times, it becomes clear that when there are already several ongoing messages and another 0.5MB message starts, the delay number tends to increase visibly. The delay number becomes more or less stable again at least after all the unscheduled packets of that long message are transmitted. Finally, the number decreases after a long message finishes. This is suggesting that a transient queue is being built up in the sender's NIC. It turns out that there is a unsigned integer underflow in QueueEstimator::getQueueSize(uint64_t) when the caller passes in a stale time that is less than QueueEstimator::currentTime and, as a result, getQueueSize incorrectly returns 0 as the estimated queue size. Therefore, in the worst case, the transport could enqueue two more full packets even though there are already two in the NIC's TX queue. But how can the caller passes in a stale time value in the first place? Well, one example would be that, in HomaTransport::tryToTransmitData(), we are using the stale time value stored in Dispatch::currentTime to save the cost of one RDTSC instruction. After fixing this bug, we don't see the delay number go up significantly and remain high for a long period like before.
Why does it take so long for a master to start sending out the reply of an EchoRpc that fits in one ALL_DATA packet? Firstly, it appears that inserting a `serverRpc` into the unordered_map `incomingRpcs` is really expensive: it can easily take more than 250ns! Also, after calling "context->workerManager→handleRpc(serverRpc);" in HomaTransport, it takes > 100ns before the RPC can be dispatched by the MasterService.