Backup and Recovery Revisited
- Ryan Stutsman
Current Design
Goals
- Fast time-to-recovery (TTR) for all data in the system
Achieving fast TTR of a single machine from a single machine is not practical because reconstituting 64 GB at disk rate requires several minutes. Thus, we need to bring more disk heads or SSDs to bear on the problem. To that end we introduce shards. A shard is, simply, a contiguous key range. The key range for each shard is chosen such that the shard represents approximately some fixed size in bytes with some hysteresis. Shards can be split/merged also to allow key ranges to move between servers for request load balancing, but this is secondary to the TTR goal. (Question: What changes if we have shards be contiguous machine/address ranges allowing objects to move between shards? One problem: dealing with client-side key-to-machine lookups.) We expect to maintain, therefore, some near constant number of shards for a single master's main memory. Each of these shards is backed-up by z other (hopefully distinct) machines.
A master for some shard receives all writes to that shard. All those writes are logged in the master and forwarded to the backups. The backups log the write in memory in precisely the same way. Once the in-memory backup log reaches a configurable length that log is committed to disk (we call these fixed length shard-specific log fragments segments). This allows us a knob to control how much buffering we need to achieve some target write bandwidth for our disks. Necessary segment sizes depend on the write bandwidth and seek latency of the logging devices. Standard disks seem to need about 6 MB segments to achieve 90% write bandwidth whereas SSDs seem they will need 128 to 512 KB segments.
Recap
Assumptions
- Must be just as durable as disk-storage
- Durable when write request returns
- Almost always in a state of crash recovery
- Recovery instantaneous and transparent
- Records of a few thousand bytes, perhaps partial updates
Failures
- Bit errors
- Single machine
- Group of machines
- Power failure
- Loss of datacenter
- Network partitions
- Byzantine failures
- Thermal emergency
Possible Solution
- Approach #4: temporarily commit to another server's RAM for speed, eventually to disk
- some form of logging in RAM and batching writes to disk + checkpointing
- need to "shard" data for each server so that many servers serve as a backup for a single master to speed recovery time
- likely, backup shards will need to be able to temporarily become masters for the data while rebuilding the master
9/30 Discussion Notes
Data Durability
- New assumption: 1-2 second non-availability when failure. How long for full reconstruction?
- Issue: Estimate reconstitution of a failed node:
- No Sharding
- 64 GB per server
- 128 MB/s disk bandwidth
- 1/10th of 10 GigE
- 512 s to read snapshot (64 GB) off a single disk
- Sharding (Want < 2s recovery)
- 512z shards needed for 1 s restore from disk to RAM
- z := # of replicas per server
- Assume 5 ms write latency
- Want 90% disk write bandwidth efficiency
- 45 ms worth of writes does ~6 MB or ~6000 records
- Must keep 512z * 6 = 3z GB of buffer to maintain 6 MB of log per shard
- How do we clean the log?
- If appending recovery may read lots of irrelevant data
- 25z s to persist outstanding log at any given time
- important in case of failure - need this much time to make everything durable
- With z = 2, ~10% overhead
- What if memory goes up? e.g. 128 GB
- Double shards, write bandwidth is static
- Still 10% overhead
- 512z shards needed for 1 s restore from disk to RAM
- No Sharding
Write Bandwidth Limitations
- ~128 MB/s => 100 MB/s @ 90% efficiency
- Assuming no cleaning overhead
- ~100k recs/sec (1 KB recs)
- ~100k/z writes/sec/disk
- z = 2 => max 50k writes/sec (20% of 1M ops/sec/server)
Questions
- Idle standbys versus homogeneous load
- Parameters - replicas (z) and shards; how do we choose them? On what granularity are they?
- Major failures: How long to bring up if we lose DC power?
- Reconstituting failed backup disks? Don't?
- Adds to the reason for more, smaller disks in a single machine
- More heads = more write bandwidth per node
- If we partition the shards to only log to a specific disk then we only have to replicate 1/4 as many shards when a single disk fails
- The downside, of course, is that disk failures will occur more often, and cost
- All backups must be able to initiate reconstruction. Why?
- Flash may be worth another look, particularly if we can play games in the FTL.
10/7 Discussion (Logging/Cleaning on Backups)
Knobs/Tradeoffs
- Time to on disk durability (TTD)
- Also determines how much "NVRAM" we need
- Memory needed to "stage" or buffer writes
- Write bandwidth - (WE is (new data amount)/(write bandwidth))
- Time to Recover a shard/machine (TTR)
- Shards are intended to speed recovery time
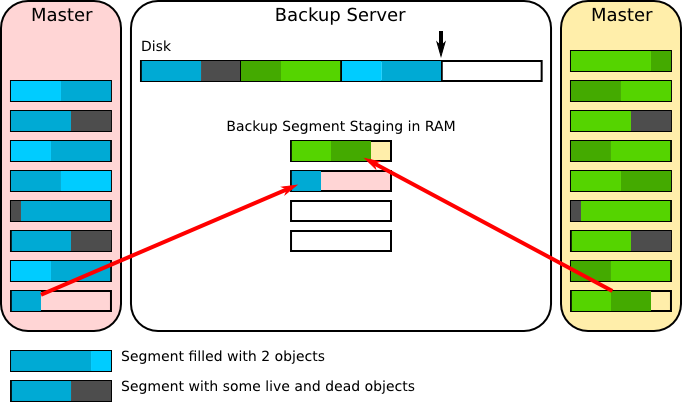
Cluster writes in chunks ("shardlets") to be batch written to segments on disk
- From previous discussion, achieves about 90% WE using 6 MB chunks per shard
- 3z GB RAM for 512 shards
- 25z TTD in case of power failure
- 90% RE providing TTR of 5z s per shard
Question remains: Log compaction or checkpointing to keep replay time from growing indefinitely
No-read LFS-style cleaning
- Masters write to 6MB shardlets in log style
- Writes are dispatched to all backups just as before
- For each shard the backup maintains a shardlet image in RAM that is in lock-step with the servers
- Once the server is done placing writes on a shardlet the backup commits it to disk
- The master recovers space from deleted or updated old values by performing compaction
- This is simply an automatic write of data from two or more old shardlets to a new one
- This allows the old shardlets to be reclaimed
- To allow the backups to reclaim the space in their on-disk logs the master sends a short trailer after finishing writes to a shardlet describing which previous shardlets are now considered "free"
- The backup maintains a catalog of where active data for each shard is (its shardlets) on disk and periodically writes this to the log
Back of the envelope
Master cleans shardlets with less than some amount of utilization
Shardlet Util. |
Disk/Master Memory Util. (Median Shardlet Util.) |
TTR Off Optimal |
Remaining Disk BW Off Optimal |
Combined WE with 90% approach from earlier |
|---|---|---|---|---|
50% |
75% |
1.33x slower |
~50% |
45% |
10% |
55% |
1.82x slower |
~88% |
80% |
- Need to take a serious look at the distribution, however. Will need to force bimodality of shardlet distribution, which will bank on some locality (temporal will be just fine)
- We tie our memory management of the server to the disk layout
- Specifically, we can't afford to have the memory be under utilized, but we won't benefit much if shardlets are dense
Fast (fine-grained, shard interleaved) logging + shardlets
- May be worth looking at some more, but back of the envelope numbers suggest that on top of the 10 s or so to restore a shard from the shardlet log another 2 minutes or so would be needed to replay the log on top of it
- A possible approach is to do shardlets are multiple granularities, but exploring this is probably only worth it if we feel we aren't inside our time budget for TTD against power failures