The role of flash memory and other technologies
- John Ousterhout
- Former user (Deleted)
- Ryan Stutsman
Some application assumptions feeding into this discussion:
- most data are written once
- read dominated workload (writes may be less than 10% or even less than 1%)
- while there is little locality, most requests refer to recent data (useful for power management
---------------------------------------------------------
Technology review
The following table compares the key characteristics of storage technologies. When possible, the values below focus on the raw potential of the underlying technology (ignoring packaging or other system issues). In other cases, I use representative numbers from current systems.
|
Capacity |
BW |
Read Latency |
Write Latency |
Cost |
Power Consumption |
|---|---|---|---|---|---|---|
Server Disk |
1TB |
100MB/s |
5ms |
5ms |
$0.2/GB |
10W idle - 15W active |
Low-end Disk |
200GB |
50MB/s |
5ms |
5ms |
$0.2/GB |
1W idle - 3W active |
Flash (NAND) |
128GB |
100MB/s |
20us |
200us |
$2/GB |
1W active |
DRAM (DIMM) |
4GB |
10GB/s |
60ns |
60ns |
$30/GB |
2W - 4W |
PCM |
50x DRAM? |
DRAM-like? |
100ns |
200ns |
disk-like? |
1W idle - 4W active? |
Caption: capacity refers to a system (not chip), BW refers to max sequential bandwidth (or channel BW), read and write latency assume random access (no locality).
Other interesting facts to keep in mind:
- Flash can be read/written at ~2KB pages, erased at ~256KB pages
- Durability: 10^6 cycles for Flash,10^8 for PCM
- Disks take seconds to get out of standby while Flash and PCM take usec.
- Flash can be a USB, SATA, PCIe, ONFI, or DIMM device. No clear winner yet.
- FTL (Flash Translation Layer) must be customized to match access patterns. This can be a 2-5x difference in access latency.
---------------------------------------------------------
System-level Comparison (from the FAWN HotOS'09 paper)
What does this mean at the system level? The FAWN HotOS paper tries to quantify both performance and total cost of ownership (TCO) for servers using DRAM, disks, and Flash when servicing Seek (memcached) and Scan (hadoop) queries. The also consider two processor scenarios: traditional CPUs (Xeon) and wimpy CPUs (Geode). The following graphs refer to Seek queries:
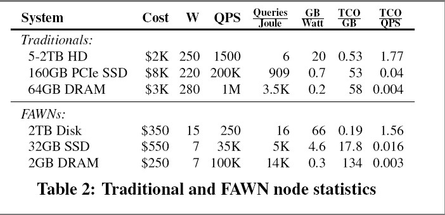
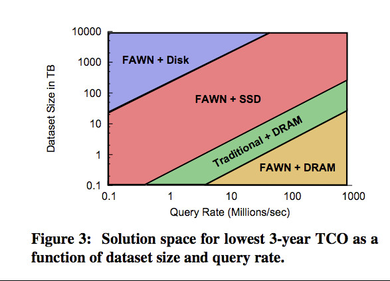
Some caveats about the FAWN graphs:
- No consideration to query latency!
- I think that the choice of components is often suboptimal or they underestimate the capabilities of some components (Flash & traditional CPUs)
- Cost of SSDs will likely drop a lot in the near future.
- No consideration for the network.
- It's not clear that their design points are balanced in any way.
---------------------------------------------------------
Flash for RAMCloud
Two options
- Use Flash as a disk replacement for durability, servicing requests from DRAM (Flash-backup)
- Use Flash to replace DRAM as the main storage technology (Flash-cloud)
Flash-backup (1) can help reduce some of the problem of the log-based persistence protocol discussed earlier in the quarter due to the better bandwidth characteristics Flash, in particular for the recovery case. Nevertheless, due to the increased cost of Flash compared to disks, if we can make the protocol work with disks using Flash is a bad idea.
Flash-cloud (2) is interesting for two reasons. First, it will reduce significantly the cost/bit for overall system. Second, it will reduce significantly the power consumption for the system, especially for the idle case. A large part of our memory devices (DRAM or Flash) will be storing bits that are not accessed frequently. Minimizing the static power of these devices would be very useful for cost and scaling reasons.
The disadvantages for Flash-cloud are the following: 1) Unacceptale RPC latency in the tens of usec (more on this later). 2) While Flash chips are commodity, Flash systems are still not. The cost of systems may be high for a while due to volume. 3) While the movement towards Flash in the enterprise is strong and will address some of the endurance and bandwidth issues for Flash, it may not be exactly what we want as they will focus competing with disk as opposed to DRAM.
Architecting Flash-cloud
Within the node, we'd need a highly parallel storage system with multiple Flash channels for bandwidth and latency purposes. PCIe is 1GB/s per lane, ONMI is 200MB/s per channel. We will have to make the FTL match our data model and access patterns. There is significant prior work here, so we'll probably need adjust one of the known protocols to our requirements. We can have some of the cores in the processor chip run our FTL protocol directly, bypassing most of the logic in a separate Flash controller (see UCSD Gordon project). This would allow us to do FTL over multiple channels, which can help with write bandwidth. Erasing pages would be done in the background of course. Since the workload is read dominated and data is write-once for the most part, there should not be that much erase activity.
At the system leve, we can now afford to replicate data across the data center. As long as the granularity is a multiple of the Flash page, the replication scheme is orthogonal.
RPC latency: From our earlier discussion, our realistic target for RPC is currently at 5usec to 20usec, depending on the choice of HW and SW. Flash would increase the read RPC by at least 20usec. The key question is whether this is acceptable for our application. Note, it will not affect the throughput goals assuming a multi-channel Flash system.
Eliminating the latency impact of erase events (2ms latency): A read may go to the same bank as an on-going erase event. While this will be rare, we need a way to reduce it's impact: if a node receives an RPC to a Flash bank that has an ongoing erase event, it can immediately forward the request to the replica node in the system. This will increase the latency by ~5us for sure. Since the probability that both nodes are erasing in the corresponding banks is extremely low, we should never see that higher latency.
Data persistence: Flash is non-volatile. However, we cannot make writes synchronous. To avoid this, we can exploit replication. On a block write, we wait for both nodes to write the data to DRAM. Then we do the actual Flash write in the background. Assuming sufficient control over the FTL algorithm and given the multiple channels, we can have very high bandwidth. There is no need for a log protocol anymore with any of the related issues. Persistence across data centers is rather orthogonal to Flash.
Research approach: Assuming the RPC latency increase is acceptable, how would we do research for Flash-Cloud? My suggestion is to use DRAM based systems to avoid dependences to the performance characteristics, avaiability, and cost of Flash systems over the next few years. We can write a software layer that emulates the characteristics of Flash on top of DRAM in order to see performance issues. Nevertheless, we will still avoid implementing any complex log protocol for persistenc. As a side project, some HW students can architect the prefect Flash system for us.
We can also avoid the emulation layer altogether by optimistically assuming that PCM will happen by the time we finish the project.