Index Split and Migration
- Ankita Kejriwal
- John Ousterhout
Owned by Ankita Kejriwal
Aim: Split indexlet I (backed by backing table T) located on M1 into I1 (backing table remains T) and I2 (new backing table T2) and migrate I2 to M2.
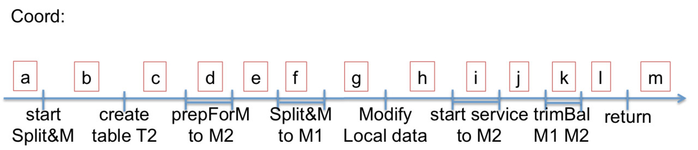
Coordinator TableManager splitAndMigrateIndexlet:
Create table T2 on M2.
Call prepForIndexletMigration on M2 for I2.
Call splitAndMigrateIndexlet on M1 for I.
In index->indexlets: Truncate I to I1 (belonging to M1) and add I2 belonging to M2. (This would also get persisted to external storage when we implement coord fault tolerance for indexes.)
Call takeIndexletOwnership on M2 for I2.
Call trimAndBalance on M1 for I1 and on M2 for I2. (Note: we’ll have these functions return right away and do the actual work asynchronously.)
M1 MasterService splitAndMigrateIndexlet:
Walk the log of T and send over RAMCloud objects that encapsulate any nodes that belong in I2. (Change the table Id of these objects from T to T2 before appending to the segment that gets sent over.) – except the last log segment.
In indexletManager list of indexlets, truncateIndexlet I to of I1.
Send the last log segment.
(Or, we could send the entire log, truncate, check log if it has grown and if it has then migrate that segment.)
M2 MasterService prepForIndexletMigration:
Add I2 (with backing table T2) to local information with state RECOVERING.
M2 MasterService takeIndexletOwnership:
Add I2 to local information with state NORMAL (and if I2 already exists, simply modify state)
M2 MasterService receiveMigrationData:
Same as pre-existing receiveMigrationData, except: Recompute nextNodeId on the receiving side as you receive segments. (See recovery to figure out how.)
M1 failures:

a: Coordinator starts split&m on whichever server (say RM) recovers this indexlet I.
b: Since we can’t tell exactly what data was transferred, the solution would be the same as a. When M2 receives the same segment (from a different server), it will do the right thing (discard new if same, keep new if it has newer version num in which case the older version num object will get cleaned up by log cleaner at some point). We’d need a mechanism on M2 to clean up old data (received from M1 before crash) when it gets a new receiveMigrationData for the same indexlet but from a different server. (can the data transfer be made idempotent, so it doesn't matter if some records get transferred muiltiple times?)
c, d: Since the coord cannot distinguish between c/d and b, the solution would be the same as b even though that results in wasted work! (wasted work is fine, as long as it doesn't happen very often and is safe)
e: No problem. We just need to call trimAndBalance at the end of indexlet recovery as coord may not have had the chance to call it yet.
Coord failures:
a: Client retries
b to l except f: If we log at b (after computing all local info for creating T2) and at l, then we can simply re-do all of these operations if we implement these operations to be idempotent. (TODO: make sure all of these operations are monotonic!)
f: Same as before. It is okay to transfer multiple times, we already have this in case of master crashes. Its probably bad to have multiple ongoing split&M requests from M1 to M2 (why? do you mean multiple requests for the same indexlet?)! Will linearizability take care of this issue? (I'm not sure; we should discuss)
m: No problem
M2 failures:
Before prepForIndexletMigration: Choose a different M3 and go from there. (Note that we'll have to have to make the client provided server id to be a hint.) Note that T2 will get recovered on a different server but I2 will not. Client retries
During one of the receiveMigrationData requests: M1 aborts and return to the coordinator. What does tabletMigration do?
Before takeIndexletOwnership: I think recovery could have taken care of it, except it won't have access to nextNodeId. So maybe we need to do the same as previous case?
After takeIndexletOwnership: Recovery will take care of it. Need to call trimAndBalance on recovery.
NOTE: What if i want to migrate the entire indexlet?